wget命令有两个作用:
- 下载文件
- 作为一个网络爬虫,将网站内容抓取下来
wget命令支持HTTP,FTP和HTTPS协议。
一、下载文件
常用用法:wget URL
含义:下载URL指向的文件
二、网络爬虫
常用用法:wget -e robots=off -r -l 2 -k -p -E -H https://mybatis.github.io/mybatis-3/zh/
含义:爬“https://mybatis.github.io”网站的内容,以“https://mybatis.github.io/mybatis-3/zh/”为起始URL
选项解释:-e robots=off:表示不遵循robots.txt文档-r:递归下载,默认深度为5-l 2:自定义递归下载的深度为2-k:转换下载得到文档中的链接,使得可正常使用-p:下载正常显示单个文档所必需的所有文件-E:自动给一些文档增加“.html”后缀-H:在递归下载时,允许跨域名
备注:
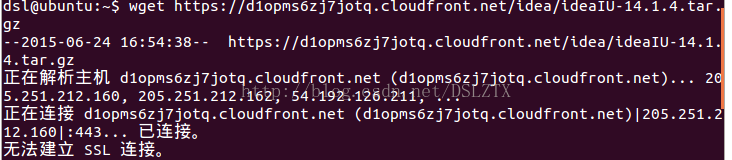
- 当URL使用HTTPS协议时,经常出现如下错误:“无法建立SSL连接”,具体如图1所示。这是因为wget在使用HTTPS协议时,默认会去验证网站的证书,而这个证书验证经常会失败。加上“–no-check-certificate”选项,就能排除掉这个错误。另外一种可能有效的解决方案是用HTTP协议替换HTTPS协议(有些网站同时支持这两种协议访问相同资源,有些网站只支持HTTPS协议或者HTTP协议)
图1
参考文献
[1]man wget
[2]https://www.gnu.org/software/wget/manual/html_node/Robot-Exclusion.html
