一、基本概念
ZooKeeper是一个为分布式应用程序提供协调服务的基础框架。
二、数据模型
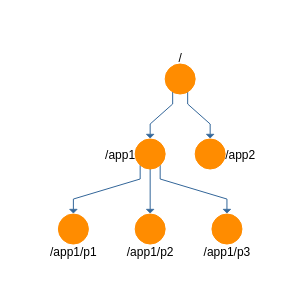
被ZooKeeper Server操纵的数据模型为一棵树,该树形如Linux文件系统下的“文件-目录树”,树中节点以“从根节点到该节点的完整路径”为表示,节点分为“znode节点”和“非znode节点”,“znode节点”存储数据,“非znode节点”不存储数据,需要注意的是,一旦“非znode节点”存储数据就成为“znode节点”,“znode节点”一旦清空数据就成为“非znode节点”,即两者并没有本质的区别。
具体如图1。
图1
三、原生提供操作保证
ZooKeeper Server原生提供如下操作保证:
- 顺序一致性。对ZooKeeper Server数据模型的操作满足“先操作先应用,后操作后应用”的性质
- 原子性。对ZooKeeper Server数据模型的操作(包括读取)满足“要么完全成功,要么完全失败”的性质
- 单一系统视图。客户端连接集群中任意一个ZooKeeper Server获取到的数据模型是完全一致的
- 可靠性。对ZooKeeper Server数据模型的更新操作会被持久保存,直到被下一次更新操作覆盖
- 时间窗口下的最新同步。客户端至多等待一个时间窗口便能获取最新同步的ZooKeeper Server数据模型
四、集群
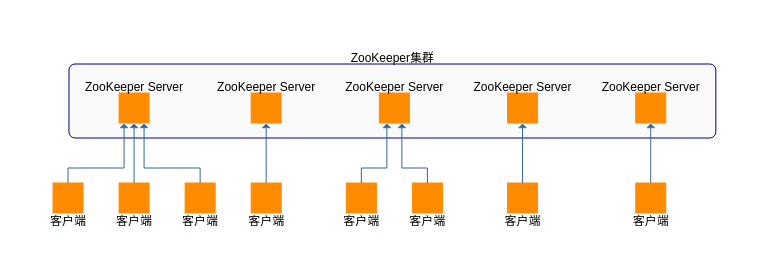
ZooKeeper集群由多台ZooKeeper Server构成,一个ZooKeeper Server指代一个ZooKeeper Server进程,多个ZooKeeper Server可运行于同一台服务器,也可运行于多台服务器,客户端以连接集群中任意一台ZooKeeper Server的形式连接该集群。如图2。
ZooKeeper集群中的ZooKeeper Server分为两种角色:Leader和Follower。关于这两种角色的详细描述见本系列的后续博文。
图2
五、性能和高可用实验
5.1、性能实验
1、实验描述
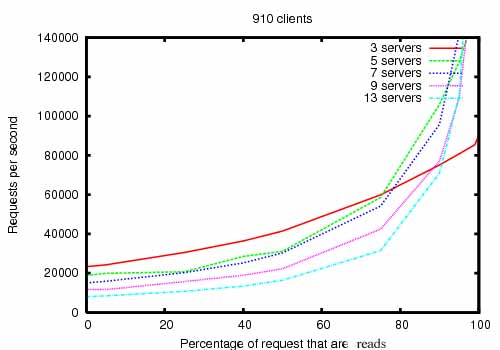
ZooKeeper集群的大小分别为:3,5,7,9,13。对于特定大小的ZooKeeper集群,不断改变读请求次数/读写请求总次数比重值,测定相应比重下的处理请求数/秒值。
另外,实验中的ZooKeeper Server版本为“3.2”,运行ZooKeeper Server的服务器的CPU为“dual 2Ghz Xeon”,具有两个SATA 15K RPM drives,运行将近910个客户端发出读写请求。
2、实验结果
见图3。
图3
3、实验结论
应用场景的读请求次数/读写请求总次数比重值越大,ZooKeeper集群每秒能够处理的请求越多。
5.2、高可用实验
1、实验描述
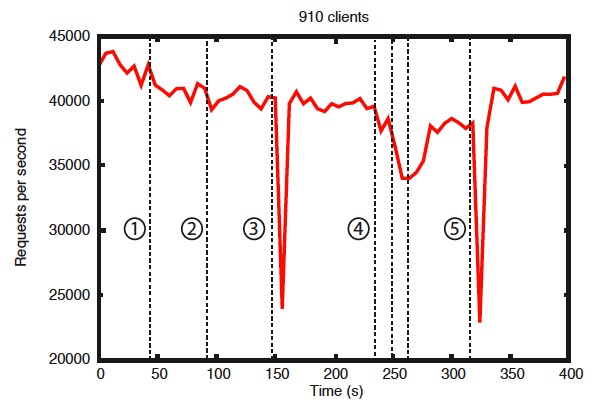
ZooKeeper集群的大小为7,即含有7个ZooKeeper Server,读请求次数/读写请求总次数比重值固定为30%。实验中的ZooKeeper Server版本为“3.2”,运行ZooKeeper Server的服务器的CPU为“dual 2Ghz Xeon”,具有两个SATA 15K RPM drives,运行将近910个客户端发出读写请求。
测定依次出现以下5种情形时,处理请求数/秒值的变化情况:
- 一个Follower ZooKeeper Server挂掉,然后恢复
- 另外一个Follower ZooKeeper Server挂掉,然后恢复
- Leader ZooKeeper Server挂掉
- 两个Follower ZooKeeper Server都挂掉,然后都恢复
- 另外一个Leader ZooKeeper Server挂掉
2、实验结果
见图4,图中标号跟上述5种情形的标号一一对应。
图4
3、实验结论
主要结论有两点:1)在Follower ZooKeeper Server的挂掉然后迅速恢复情形中,处理请求数/秒未产生较大波动;2)在Leader ZooKeeper Server的挂掉情形中,在重新选举Leader ZooKeeper Server的时间区间内,处理请求数/秒大幅度降低,但是一旦选举完成,处理请求数/秒即迅速恢复到正常水平值,另外可发现,Leader ZooKeeper Server的重新选举过程能够非常快地完成。
文档地址:https://zookeeper.apache.org/doc/r3.4.10/zookeeperOver.html
