一、常用用法
1 | df [-i] [-h] [FILE] |
二、含义与选项
2.1、含义
打印“FILE”文件所在文件系统的容量使用情况;如果“FILE”参数未指定,则打印所有文件系统的容量使用情况。
2.2、选项
“-i”:加上“-i”选项,打印文件系统中Inode节点集合容量的使用情况;否则,打印文件系统中Block节点集合容量的使用情况。
“-h”:以人类可读形式展现容量。
“FILE”:位于目标文件系统上的文件,如果“FILE”参数未指定,则打印所有文件系统的容量使用情况。
三、“-i”和“-h”选项
文件系统容量分为:Block节点集合容量和Inode节点集合容量。
3.1、Block节点集合容量
默认情况下打印文件系统上Block节点集合容量的情况。
3.1.1、不加“-h”选项
示例如图1。
图1
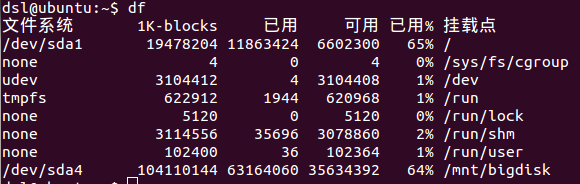
“1K-blocks”中的“1K”表示“以1K字节大小作为基本统计单元”,其中的“block”不是指代“Inode/Block节点体系”中的“Block节点”,而只是“基本统计单元”的含义。值19478204表示“基本统计单元总数量为19478204个”,即容量约为18G(“19478204*1K/1024/1024/1024”约等于“18G”)。
“已用”表示已使用基本统计单元数量。
“可用”表示可使用基本统计单元数量。
“已用%”表示“已使用基本统计单元数量”与“基本统计单元总数量”的比值。
3.1.2、加“-h”选项
加“-h”选项,以人类可读形式展现容量。示例如图2。
图2
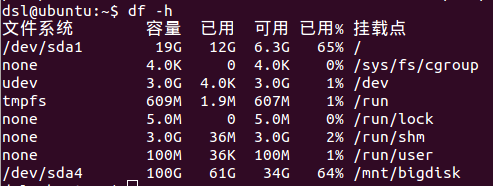
“容量”表示容量总大小。
“已用”表示已使用容量。
“可用”表示可使用容量。
“已用%”表示“已使用容量”与“容量总大小”的比值。
3.2、Inode节点集合容量
加上“-i”选项打印Inode节点集合容量的情况。
3.2.1、不加“-h”选项
示例如图3。
图3
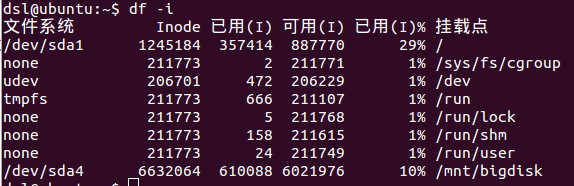
“Inode”表示Inode节点总数量。
“已用(I)”表示已使用Inode节点数量。
“可用(I)”表示可使用Inode节点数量。
“已用(I)%”表示“已使用Inode节点数量”与“Inode节点总数量”的比值。
3.2.2、加“-h”选项
加“-h”选项,以人类可读形式展现容量。示例如图4。
图4
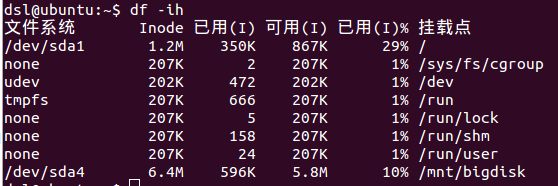
“Inode”表示Inode节点总数量,以人类可读形式展现。
“已用(I)”表示已使用Inode节点数量,以人类可读形式展现。
“可用(I)”表示可使用Inode节点数量,以人类可读形式展现。
“已用(I)%”表示“已使用Inode节点数量”与“Inode节点总数量”的比值。
四、其他
4.1、几个等式的不成立
需要注意的是,打印信息中,几个理论上应该成立的等式并不成立:1K-blocks=已用+可用,已用%=已用/1K-blocks*100%,容量=已用+可用,已用%=已用/容量*100%,Inode=已用(I)+可用(I)和已用(I)%=已用(I)/Inode*100%。作者不知道具体实现细节,因此不知道具体原因。
4.2、“df”命令与“ls,stat,du”命令的差异
df命令与ls,stat,du命令的差异:
df命令面向文件系统,ls,stat,du命令面向文件(包括“一般文件”和“目录文件”)- 在Block节点集合容量的范畴下,
ls,stat,du命令统计“一般文件”的容量是基于“使用大小”的,统计“目录文件”的容量是基于“占用大小”的;df命令的统计是基于“占用大小”的(关于文件的“使用大小”和“占用大小”可见《Ext文件系统中,文件的“占用大小”和“使用大小”》) df命令跟ls,stat,du命令不一样,加上“-h”选项并不会产生“计算误差”,因为在df命令中,加上“-h”选项导致的转换是在最终统计后直接进行的
参考文献: [1]man df
