一、基本概念
Kafka是一个面向“消息流”的系统,它能够进行消息流的“发布,存储,处理和消费”。在实际生产环境中,Kafka一般以Kafka集群的形式被应用。
二、设计简介
2.1、主题
特定的消息流以主题名进行指代,即主题名作为特定消息流的名称,不同主题名对应的消息流互相独立。消息流中的消息由“键,值,时间戳”3部分构成。
Kafka集群性能跟主题存储所占用大小常系数相关,因此,主题存储所占用大小不是影响Kafka集群性能的主要因素。
2.2、API提供与应用程序角色
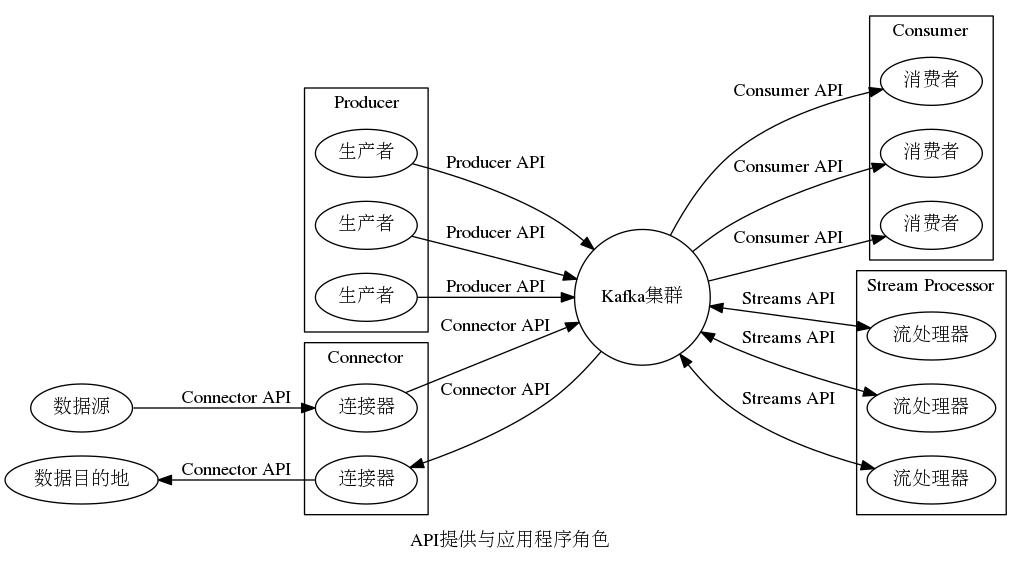
Kafka提供4类API:Producer API,Consumer API,Streams API,Connector API,基于这4类API编程的应用程序分别具有以下4种角色:生产者,消费者,流处理器,连接器。关于这4类API的简要说明见表1,示意图见图1。
表1
| API | 基于编程应用程序角色 | 简要说明 |
|---|---|---|
| Producer API | 生产者 | 允许生产者向主题发布消息 |
| Consumer API | 消费者 | 允许消费者从主题订阅消息 |
| Streams API | 流处理器 | 允许流处理器从主题订阅消息,处理消息,向主题发布消息 |
| Connector API | 连接器 | 允许使用连接器从数据源(比如日志文件,Mysql,HDFS等)导入数据到Kafka的消息流,从Kafka的消息流导出数据到数据目的地(比如日志文件,Mysql,HDFS等) |
图1
2.3、“发布-订阅”模型中的数据流路径
根据Kafka提供的API,使用Kafka有3种模型:发布-订阅模型(基于Producer API和Consumer API),流处理模型(基于Streams API)和连接器模型(基于Connector API)。
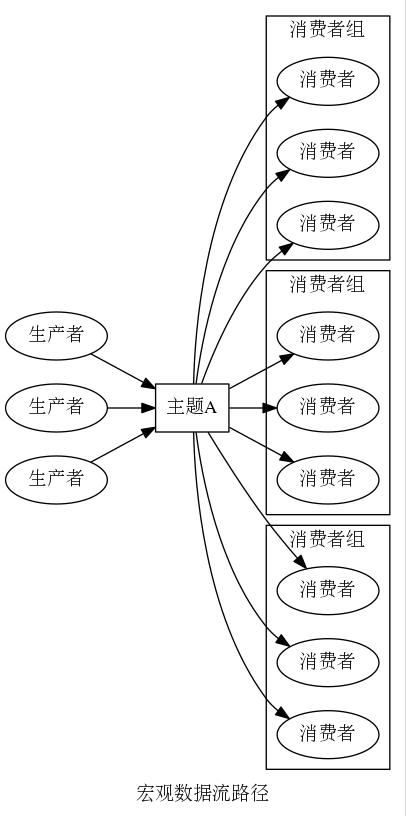
最常见的使用模型是发布-订阅模型,关于该模型的几点描述(以1个特定的主题A为例)如下:
- 1到多个生产者向主题A发布消息
- 消息消费的基本单元是“消费者组”,而不是“消费者”。基于消息消费的角度,订阅主题A的消费者组之间互相独立,订阅主题A的同一个消费者组内的消费者之间互相排斥,即“主题A对应的消息流中的任意一个消息会被所有订阅消费者组消费,却只会被订阅消费者组内的一个消费者消费”
该模型的数据流路径有“宏观”和“微观”之分。
2.3.1、宏观数据流路径
宏观数据流路径如上所述,示意图如图2所示。
图2
2.3.2、微观数据流路径
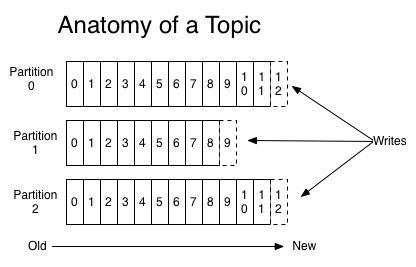
微观上,基于“负载均衡”考虑,主题由多个分区构成,同一个主题的所有分区均衡分布于Kafka集群的不同节点上,基于“容错性”考虑,对于“分区”,存在一定数量的“备份分区”,一旦“分区”不能正常工作,会选择相应的一个“备份分区”成为新“分区”。分区可被看作一个存储消息的队列,新消息只能被添加于队尾,新消息会被分配一个该队列中唯一的标识数字(被称为“offset”)。分区消息删除机制跟“消息是否被消费”无关,当cleanup.policy=delete时,根据配置的有效期或者大小,进行分区消息的删除;当cleanup.policy=compact时,根据“是否能够进行压缩”,进行分区消息的删除。主题分区结构示意图如图3所示。
图3
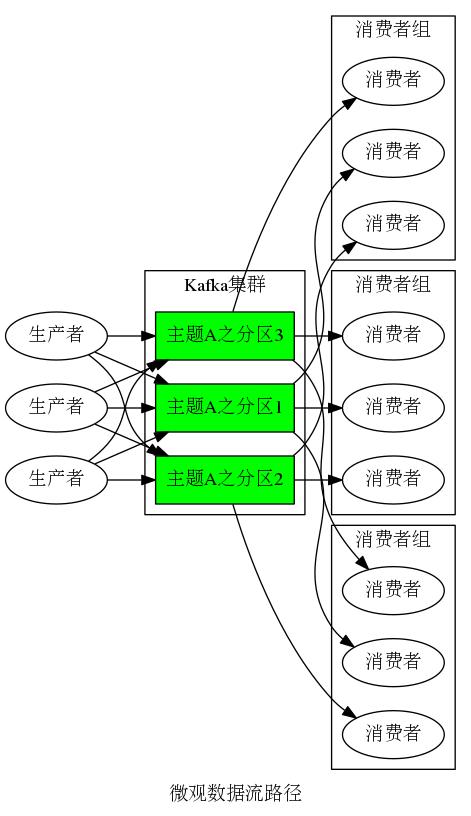
生产者向主题发布消息,微观上,基于“负载均衡”考虑,生产者将自身的消息基于一定策略(比如“哈希函数”)均衡发布到主题的不同分区。
消费者组从主题订阅消息,微观上,基于“负载均衡”考虑,主题的任意一个分区被以一定策略绑定到订阅消费者组的某个特定消费者,分区的消息只被订阅消费者组内的相应绑定消费者消费,基于“负载均衡”考虑,这种绑定关系尽量均衡分布于订阅消费者组内的不同消费者,这种绑定关系是动态的以应对消费者组内消费者的增加和减少,具体由Kafka集群控制。基于上述绑定机制,分区的数量必须大于等于消费者组内的消费者数量,否则便会存在未绑定分区的消费者。另外,消费者被设计可自由消费分区中任意一个消息。
基于上述描述,微观数据流路径示意图如图4所示。
图4
2.4、设计保证
Kafka提供以下几点设计保证:
- 同一个生产者向同一个主题的同一个分区先后发布两个消息,在该分区中存储这两个消息时保持相同的先后顺序
- 消费者所观察到的分区中消息的先后顺序,就是该分区中对应消息存储的先后顺序
- 对于主题,假如配置分区的备份因子值为
N,则共有N个“分区或者备份分区”,因此至多允许N-1个“分区或者备份分区”不能正常工作,而不丢失消息数据
三、具体应用
3.1、发布-订阅模型具体应用
网站行为收集系统,性能数据收集系统,日志收集系统,事件变化日志系统等。同类产品有ZeroMQ,RabbitMQ,ActiveMQ等。
3.2、流处理模型具体应用
新闻素材收集处理推荐系统。同类产品有Apache Storm,Apache Samza等。
3.3、连接器模型具体应用
“导入Mysql数据,导出到HDFS”系统,“导入日志数据,导出到Mysql”系统。同类产品有Flume,Scribe等。
四、快速开始
4.1、搭建Kafka集群
Kafka主目录下有文件“config/server.properties”,它是Kafka自带的一份完整的配置文件,当下我们只需关注其中的4个配置参数:broker.id,listeners,log.dir,zookeeper.connect。关于这4个配置参数的描述见表2。
表2
| 配置参数 | 描述 |
|---|---|
| broker.id | 整数,本Kafka节点在Kafka集群中的唯一标识符 |
| listeners | 本Kafka节点监听地址,客户端通过该地址访问本Kafka节点 |
| log.dir | 本Kafka节点的日志存放目录 |
| zookeeper.connect | Kafka集群使用ZooKeeper集群提供的服务。本配置参数配置ZooKeeper集群客户端监听地址或者地址列表(以逗号隔开) |
假定现有机器A,B,C,D,E,F,在A,B,C上运行ZooKeeper集群(客户端监听端口号都为2181)。
在D上,Kafka主目录下“config/server.properties”文件内上述4个配置参数的配置值如下:
1 | broker.id=0 |
执行bin/kafka-server-start.sh config/server.properties命令,运行D上的Kafka节点。
在E上,Kafka主目录下“config/server.properties”文件内上述4个配置参数的配置值如下:
1 | broker.id=1 |
执行bin/kafka-server-start.sh config/server.properties命令,运行E上的Kafka节点。
在F上,Kafka主目录下“config/server.properties”文件内上述4个配置参数的配置值如下:
1 | broker.id=2 |
执行bin/kafka-server-start.sh config/server.properties命令,运行F上的Kafka节点。
4.2、3种Kafka使用模型初体验
4.2.1、发布-订阅模型初体验
1、创建主题
命令如下:
1 | bin/kafka-topics.sh --create --zookeeper A:2181 --replication-factor 3 --partitions 3 --topic my-replicated-topic |
“–zookeeper A:2181”:通过ZooKeeper集群中的配置地址连接到Kafka集群,具体ZooKeeper地址是ZooKeeper集群中任意一个(多个)ZooKeeper节点的地址(地址列表)
“–replication-factor 3”:分区的备份因子值,当值为N时,表示“每个分区都有N-1个备份分区”
“–partitions 3”:配置主题的分区数量
“–topic my-replicated-topic”:配置主题名称
2、生产者向主题发布消息
命令如下:
1 | bin/kafka-console-producer.sh --broker-list D:9092 --topic my-replicated-topic |
“–broker-list D:9092”:Kafka集群内节点地址或者地址列表(以逗号隔开)
“–topic my-replicated-topic”:指定主题
3、消费者从主题订阅消息
命令如下(可认为,消费者组只含有一个消费者):
1 | bin/kafka-console-consumer.sh --bootstrap-server D:9092 --from-beginning --topic my-replicated-topic |
“–bootstrap-server D:9092”:Kafka集群内节点地址
“–from-beginning”:从头开始订阅消费主题消息
“–topic my-replicated-topic”:指定主题
4.2.2、流处理模型初体验
以一个简单的“单词统计”应用程序为例,该独立的应用程序从Kafka集群的“streams-plaintext-input”主题读取单词数据,并将实时统计结果发布到Kafka集群的“streams-wordcount-output”主题。流处理模型初体验详细内容见链接。
1、创建数据源主题
创建Kafka集群的“streams-plaintext-input”主题,命令为:
1 | bin/kafka-topics.sh --create --zookeeper A:2181 --replication-factor 3 --partitions 3 --topic streams-plaintext-input |
2、创建数据目的地主题
创建Kafka集群的“streams-wordcount-output”主题,命令为:
1 | bin/kafka-topics.sh --create --zookeeper A:2181 --replication-factor 3 --partitions 3 --topic streams-wordcount-output |
3、运行“单词统计”应用程序
命令为:
1 | bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo |
4、运行生产者向数据源主题发布消息
命令为:
1 | bin/kafka-console-producer.sh --broker-list D:9092 --topic streams-plaintext-input |
运行对应于“streams-plaintext-input”主题的生产者,依次输入“all streams lead to kafka”,“hello kafka streams”,“join kafka summit”发布消息。
5、运行消费者从数据目的地主题订阅消息
命令为:
1 | bin/kafka-console-consumer.sh --bootstrap-server D:9092 --topic streams-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer |
运行对应于“streams-wordcount-output”主题的消费者,获取“单词统计”应用程序的实时统计结果。
4.2.3、连接器模型初体验
以一个简单的“数据源是普通文本文件,数据目的地是普通文本文件”的应用程序为例,该独立的应用程序运行两个“连接器”:“Source Connector”和“Sink Connector”。“Source Connector”从普通文本文件读取数据并将其以消息的形式发布到Kafka集群的某个主题,“Sink Connector”从Kafka集群的某个主题订阅消费消息并将其写入普通文本文件。
1、运行独立应用程序
命令如下:
1 | bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties |
“config/connect-standalone.properties”:本独立应用程序的配置文件,配置了Kafka集群地址等参数,比如bootstrap.servers=D:9092
“config/connect-file-source.properties”:本独立应用程序调用的“Source Connector”的配置文件,默认配置按行读取“test.txt”文件的字符串作为结构化消息的主体内容,并将消息发布到Kafka集群的“connect-test”主题
“config/connect-file-sink.properties”:本独立应用程序调用的“Sink Connector”的配置文件,默认配置订阅Kafka集群的“connect-test”主题,消费解析消息并将解析得到的主体内容按行写入“test.sink.txt”文件
2、查看“connect-test”主题内容
命令如下:
1 | bin/kafka-console-consumer.sh --bootstrap-server D:9092 --from-beginning --topic connect-test |
五、生态系统
Kafka生态系统详细内容见链接。
文档地址:https://kafka.apache.org/0110/documentation.html#gettingStarted
