高速缓存,英文名为“CPU Cache”,下面可简称缓存/Cache。
一、为什么要使用高速缓存
使用高速缓存基于的理由有两点:
- 局部性原理,包括“时间局部性”和“空间局部性”。空间局部性:假如当前正在访问地址A,那么接下来访问A的邻近地址的可能性非常大;时间局部性:在一段时间内,被访问过的地址可能会被多次访问
- 一方面,高速缓存的存取速度大于主存的存取速度,利用高速缓存,可以提升CPU存取数据的效率;另外一方面,高速缓存的成本大于主存,用高速缓存完全替代主存是不经济的。因此,基于“时间局部性”原理,可使用高速缓存缓存正在存取的主存数据,一旦后续命中缓存,CPU可直接存取高速缓存,获得存取速度的提升;又基于“空间局部性”原理,使用高速缓存缓存主存数据时,不要只缓存1个字节,而是要缓存一定数量的字节,这就是Cache Line机制产生的原因
二、分类
一般分为:L1高速缓存,L2高速缓存,L3高速缓存。
一般情况下,L1高速缓存和L2高速缓存属于“CPU核”私有,L3高速缓存属于“多CPU核”共享。
三、缓存行
Cache Line:缓存行,如上所述,使用高速缓存缓存主存数据时需要缓存一定数量的字节,这就是一个Cache Line。一般情况下,一个Cache Line有32或者64个字节。
使用高速缓存缓存主存的数据,既然高速缓存以Cache Line为基本单元,那么主存中就得有相应的基本单元——数据块。一个数据块与一个Cache Line对应,它们的字节数相等,加载一个数据块的数据到一个Cache Line。
四、高速缓存Cache Line与主存数据块的映射
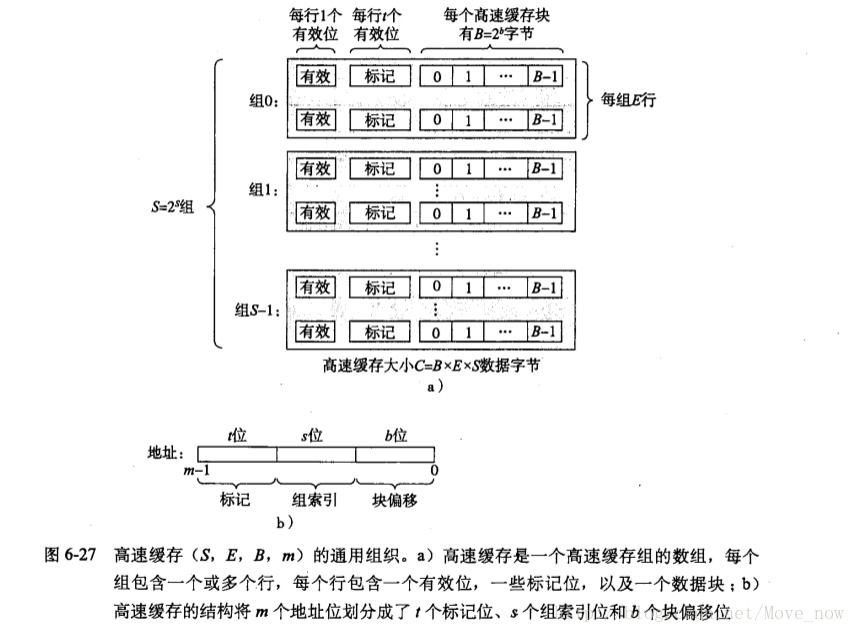
假设高速缓存共有s+e位地址:其中s表示共有2^s=S个组;e表示每组共有2^e=E个Cache Line。
每个Cache Line有1+t个数据位和2^b=B个字节:1个标记位,表示是否有效,“有效”则Cache Line命中,“无效”则Cache Line未命中,等价于“未加载”;t个标记位,其含义在后面介绍;然后一个Cache Line共有2^b=B个字节。
主存共有m位地址,以数据块作为基本单元,一个数据块跟一个Cache Line对应故同样有2^b=B个字节,那么就有2^(m-b)个数据块。
高速缓存Cache Line与主存数据块的映射方法描述如下:首先通过取模运算,将主存中的一个数据块映射到高速缓存中的某一个特定组,然后该数据块被允许可映射到该组内的任一个Cache Line。
取模运算具体为2^(m-b) mod 2^s,经过分析可知,要想建立Cache Line与数据块的一一映射关系,还需要保存主存地址的m-b-s位信息,上述提到的标记位t就是用来保存这个信息的,因此,t=m-b-s。
示意图如图1。
图1
4.1、组相联映射
s和e都不为0。是“直接映射”和“全相联映射”的折衷方案。
4.2、直接映射
s不为0,e为0,即每组只有一个Cache Line。
优点:最简单的映射方式,实现硬件简单,成本低,地址映射变换速度快(因为在找到组后,不需要再比较Cache Line),而且由于每组只有一个Cache Line,无需替换算法而是直接替换。
缺点:Cache Line冲突率高,也即高速缓存利用率低,高速缓存命中率低。
4.3、全相联映射
s为0,即只有1个组,e不为0。
优点:高速缓存利用率高,高速缓存命中率高。
缺点:当判断一个主存地址是否被命中时,需要遍历每一个Cache Line,代价非常高。
五、具体运转机制
5.1、读策略
当CPU需要从主存中读取数据时,如果在高速缓存中存在相应数据块数据(即缓存命中),那么直接从高速缓存中读取数据;如果不存在(即缓存不命中),那么先将主存中的相应数据块载入高速缓存,然后再从高速缓存中读取数据。
5.2、写策略[2]
主要有两种:Write Back(写回)和Write Through(写通)。
总的示意图如图2。
图2
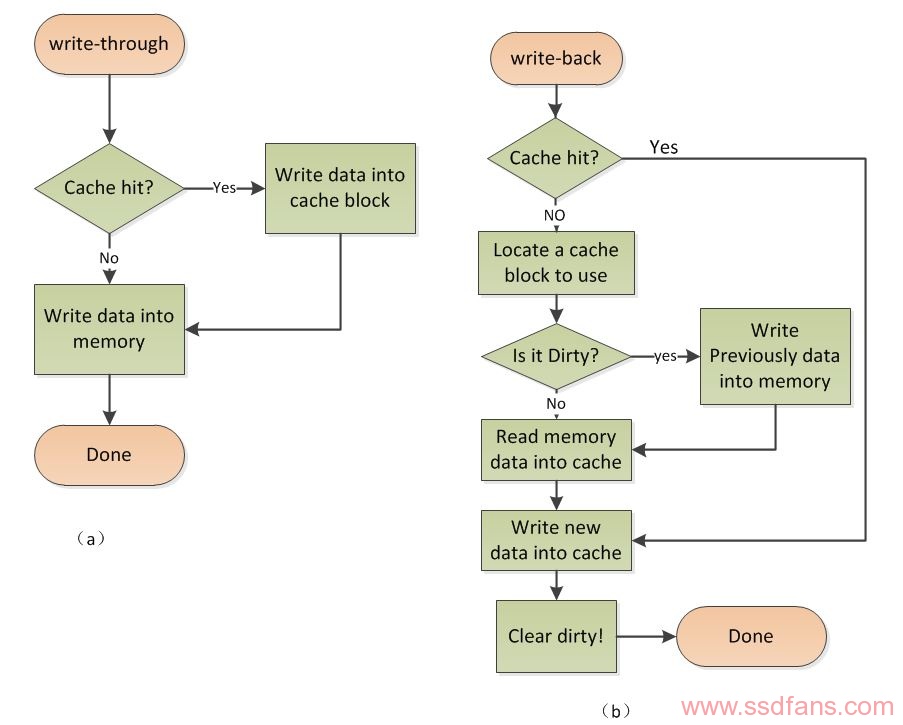
5.2.1、Write Back
分为两种情形:Cache写命中和Cache写未命中。示意图如图2中b。
1、Cache写命中
当CPU对Cache写命中时,只修改Cache Line的内容而不立即写入主存,只当该Cache Line被替换出去时才写回主存。
这种策略使得Cache在CPU与主存之间,不仅起到了读缓存作用,也起到了写缓存作用,在读和写的过程中都减少了对主存的访问次数。
不过为支持这种机制,Cache Line必须再额外配置一个修改标记位,以表征该Cache Line是否被修改过。当某个Cache Line需要被替换出去的时候,根据修改标记位决定是否需要写回主存。
2、Cache写未命中
当CPU对Cache写未命中时,首先将相应的主存数据块加载到Cache Line(基于“后续对该Cache Line进行存取的可能性很大”的假设),然后跟“Cache写命中”一样,只修改Cache Line的内容而不立即写入主存,只当该Cache Line被替换出去时才写回主存。
为什么不在加载主存数据块到Cache Line的过程中顺便将修改写回主存的原因是:加载主存数据块到Cache Line的过程中很有可能需要替换出去一个Cache Line,而该Cache Line又很有可能需要写回主存,这需要竞争总线,为降低该操作的时延而“在加载主存数据块到Cache Line的过程中不顺便将修改写回主存避免竞争总线”。
5.2.2、Write Through
分为两种情形:Cache写命中和Cache写未命中。示意图如图2中a(当Cache写未命中时,采取WTNWA策略)。
1、Cache写命中
当CPU对Cache写命中时,同时写主存和Cache,因此主存和Cache总是保持同步,这种机制实现简单。但是由于每次写都要写主存,导致总线工作繁忙,降低主存的存取速度。
比如,在一个一段程序频繁修改一个局部变量的场景中,局部变量并不会被共享,因此,每次修改都直接写主存是白白占用了总线时间。
2、Cache写未命中
当CPU对Cache写未命中时,直接向主存写入,对于此时是否将修改过的主存数据块加载到Cache Line,存在两种选择:1)加载,称为“Write–Through–with–Write–Allocate”,简称为“WTWA”;2)不加载,称为“Write-Through–with-NO-Write–Allocate”,简称为“WTNWA”。
方案一操作复杂,但是缓存命中率高;方案二操作简单,但是缓存命中率低。
5.3、替换策略
当加载一个主存数据块到Cache时,根据映射策略选择一个标的Cache Line:当映射策略为“直接映射”时,标的Cache Line只有一个,无需任何替换算法;除此之外,标的Cache组内所有Cache Line都可成为标的Cache Line,如果存在空Cache Line,那么无需替换,直接加载到该空Cache Line,否则,需要替换算法进行替换。
理想的替换算法应该是:替换时保留最近将要使用的Cache Line,这样才能获得很高的缓存命中率。
目前,使用较多的替换算法有:随机(RANDOM)替换、先入先出(FIFO)替换和近期最少使用(LRU)替换。
备注:
- 所有替换算法都由硬件电路实现,这样才能获得最佳性能
5.3.1、随机(RANDOM)替换算法
随机选择缓存组内的Cache Line进行替换。优点:实现简单,系统开销小;缺点:不是理想替换算法。
5.3.2、先入先出(FIFO)替换算法
根据先入先出策略选择缓存组内的Cache Line进行替换,需要额外保存先入先出信息。优点:实现简单,系统开销小;缺点:不是理想替换算法。
5.3.3、近期最少使用(LRU)替换算法
根据近期最少使用策略选择缓存组内的Cache Line进行替换,需要额外随时记录Cache Line的使用情况,以便确定哪个Cache Line是近期最少使用的。优点:最接近于理想替换算法;缺点:实现复杂,系统开销大。
参考文献
[1]CSAPP:《Computer Systems: A Programmer’s Perspective》
[2]http://www.ssdfans.com/blog/2018/07/27/%E6%B7%B1%E5%85%A5%E6%B5%85%E5%87%BAcache%E5%86%99%E7%AD%96%E7%95%A5/
[3]https://blog.csdn.net/hs794502825/article/details/37937949
[4]https://blog.csdn.net/dongyanxia1000/article/details/53392315
[5]https://blog.csdn.net/dark5669/article/details/53895744
[6]https://blog.csdn.net/Move_now/article/details/68488996
